The idea of Step Functions is to define cloud backend processes as visualizable graphs and to reduce the number of traditional lines of code you have to write. For example, customer orders are a typical application for Step Functions. When you model your orders using Step Functions, you're not just storing the order information in a database. You are also defining how the order is processed from payment to fulfillment according to predefined rules.
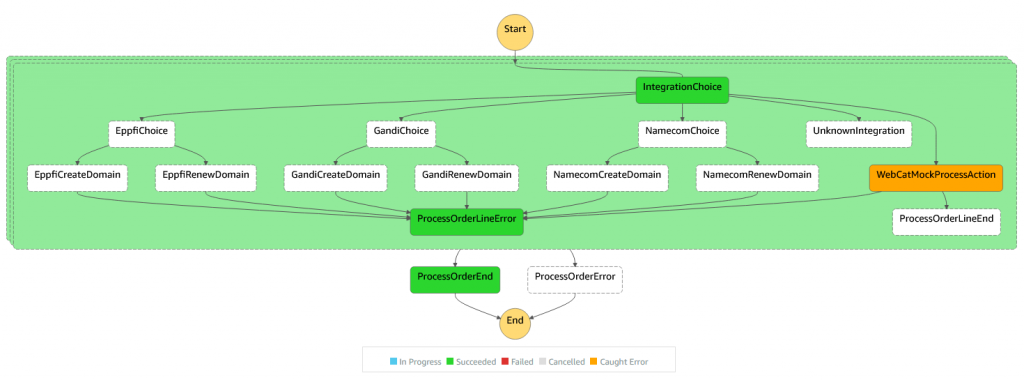
Technically you are defining state machines and state transition rules. These states typically represent integrations between backend systems (internal and external) and sometimes human processes such as physically delivering products by mail.
I talk about Step Functions here, but that is just the Amazon product. Azure has Durable Functions and most other cloud platforms probably have something similar. The interesting thing to me is the new low-code programming paradigm that they are enabling.
The Big Promise
When you define your business processes with Step Functions, you gain a few important abilities:
- Visualization: It's easy to render the business process as a visual graph. In fact, AWS Console does this automatically for all Step Function executions.
- Observability: You can see the current state of your business process and what's going to happen next. You can also track errors in once central place.
- Retrying: When an error occurs in an operation in the middle of the business process, you can have rules to automatically retry the operation before giving up.
- Error handling: When an error occurs in the middle of your business process, the entire process is aborted. The error is not mysteriously lost in a swamp of log files. You don't end up in a "nothing happens" state because a Lambda function didn't trigger the next SQS or SNS message.
- Scalability: If your business process involves operations that can run in parallel, Step Functions will let you do that and collect the results. The process will continue when all the parallel steps have completed.
- Modularity: When your business process is defined as a collection of independent states whose input and output are JSON objects, it becomes possible to exchange the implementation of any state with something else that consumes and emits the same JSON objects.
All these abilities are features that you could program yourself from scratch, but now you don't have to. Instead, you define the broad outline of your business process using Amazon States Language (ASL). Then you add small pieces of actual code using TypeScript or Python or whatever language you wish to use.
The price is a learning curve. The ASL language itself is not complicated, but figuring out how to properly use it can sometimes be. The most challenging issue is how to model your state inputs and outputs. They are just regular JSON objects, but the way that Step Functions can process them is rather limited and the objects can get complicated.
The Challenge of Increasing Complexity
You will quickly experience the complexity of managing state inputs and outputs when you define a bigger Step Function that involves many states. Perhaps it has a Map state, a few Choice states, some Lambda function executions and some external Step Function executions. All these different operations return their outputs in different ways, and the state that is flowing through your state machine is affected by them.
For example, Lambda function output is received as a Payload object, which you typically assign to a Result object using ResultPath. If your Lambda function returns an object like {"hello": "world"}, the actual output will then be {"Result": {"Payload": {"hello": "world"}}.
If you happened to call that Lambda function from a Map state, you will actually get an array of those output objects. And since you again need to use ResultPath to preserve the original Step Function input, the output will look something like {"Result": [{"Result": {"Payload": {"hello": "world"}}, {"Result": {"Payload": {"hello": "world"}}]}.
To makes things a little more complicated, your states can also have Catch handlers which are called when an error occurs. They will receive the error object and they can return a valid output if they decide that the execution can continue. This introduces a new variation to your state machine, so sometimes the output might be {"Error": {"Error": "xxx", "Cause": "yyy"}}.
So, in my view, the main problem of Step Functions is how to mentally comprehend the exact structure of the input and output objects at any given state of the state machine. You very easily lose track of all those Results and Payloads and Errors. Then you typically start guessing and tweaking the inputs and outputs until the system appears to work. When your Step Function is complicated enough, you can't manually test every possible state (including the error states), and you inevitably start introducing bugs to the logic.
How to Manage Complexity
The way that Step Functions pass an input object to the next state is basically like an undocumented API with no schema definition and no type checking. In my view, this is currently its biggest shortcoming. Lack of input/output schema definitions makes it difficult to develop complex state machines. It is entirely up to the developer to write down the schemas in comments or in some external documentation. That quickly gets verbose and inconvenient.
If Step Functions had built-in schemas for state input and output, you could validate the state transitions during development. For instance, when you use Visual Studio Code to develop your Step Functions, you might immediately see red errors when you're trying to pass an invalid input to a state. This could also be a deploy-time feature of AWS CDK. It would refuse to deploy a state machine when it detected invalid state inputs. It would basically work like TypeScript type checking.
Another approach, perhaps complementary to schema validation, would be to visualize the inputs and outputs during development. Tooltip hints in Visual Studio Code would tell you what kind of input a state expects, what kind of output a state emits, and how they are transformed by the Step Functions directives like InputPath, OutputPath, ResultPath and ResultSelector.
A third solution, also complementary, would be to replace the current input / output directives with a more flexible JSON transformation feature. Currently, Step Functions can only "prune" JSON objects by picking one or more attributes from an output object. It would be much more helpful (although also much more complicated) to have transformation functionality similar to the jq CLI command. The jq command can process JSON objects and arrays dynamically and synthesize new objects from their attributes. That would let you "flatten" the outputs and to synthesize the inputs with more freedom, ultimately keeping the actual state as simple as possible.
The Next Level
I believe that Step Functions will not be programmed using code in the future. There will be visual tools for designing business processes and their state transitions. These tools will include schema validation features to manage the complexity issues I described earlier. They will make it foolproof to create Step Functions that will not fail because of an input/output syntax error. They will also warn you when they detect other logical errors in your process definition.
The new development tools will also let you embed TypeScript code (or other languages if you wish) into the state machine states where traditional programming is required. It will be possible to edit the entire business process visually, and drill down to the low-level code with a simple click. This will be either browser-based or happen inside Visual Studio Code.
I don't believe in the idea of extending Step Functions with lower-level features that would replace manual programming completely. It's not practical to write every single line of code with visual logic. Step Functions will define the broad strokes of your business processes and let you add more detailed logic using traditional code. The amount of traditional code will decrease but never quite reach zero.
I believe that the new visual tools will also cover other parts of your cloud infrastructure than just Step Functions. Ideally, you'll use the same tools to design your REST APIs and GraphQL APIs and to define shared JSON data models and DynamoDB data tables. There will be some parts of your cloud stack that are not convenient to define using visual tools. You'll define them using traditional AWS CDK code blocks or CloudFormation fragments when necessary.
With the increasing popularity of AWS CDK, more and more reusable abstract cloud components will be available. When someone has already designed a suitable Step Function or a Lambda function, or a more complicated AWS CDK Construct that solves your problem, you can just add it to your project. The new visual tools will need to be modular in this sense.
The overall goal will be to reduce unnecessary manual work (repetitively typing code) and also to reduce the cognitive load of remembering all the details of your business process in your head. Eventually you'll be able to design and manage cloud-based systems using comfortable visual tools that let you easily zoom in to the low-level code when it's necessary. This ultimately means less work and faster development times.
If you'd like to discuss this topic, you can just tweet to @kennu.